Recently, I was preparing to nonstop an important bottom-of-funnel (BOFU) email to our audience. I had 2 taxable lines and couldn‘t determine which 1 would execute better.

Naturally, I thought, "Let’s A/B trial them!" However, our email marketer quickly pointed retired a limitation I hadn't considered:

At first, this seemed counterintuitive. Surely 5,000 subscribers was capable to tally a elemental trial betwixt 2 taxable lines?
This speech led maine down a fascinating rabbit spread into nan world of statistical value and why it matters truthful overmuch successful trading decisions.
![Instagram Engagement Report [Free Download]](https://no-cache.hubspot.com/cta/default/53/9294dd33-9827-4b39-8fc2-b7fbece7fdb9.png)
While devices for illustration HubSpot’s free statistical value calculator tin make nan mathematics easier, knowing what they cipher and really it impacts your strategy is invaluable.
Below, I’ll break down statistical value pinch a real-world example, giving you nan devices to make smarter, data-driven decisions successful your trading campaigns.
Table of Contents
- What is statistical significance?
- How to Calculate and Determine Statistical Significance
- Why is statistical value important?
- How to Test for Statistical Significance: My Quick Decision Framework
What is statistical significance?
In marketing, statistical value is erstwhile nan results of your investigation show that nan relationships betwixt nan variables you're testing (like conversion complaint and landing page type) aren't random; they power each other.
Why is statistical value important?
Statistical value is for illustration a truth detector for your data. It helps you find if nan quality betwixt immoderate 2 options — for illustration your taxable lines — is apt a existent aliases random chance.
Think of it for illustration flipping a coin. If you flip it 5 times and get heads 4 times, does that mean your coin is biased? Probably not.
But if you flip it 1,000 times and get heads 800 times, now you mightiness beryllium onto something.
That's nan domiciled statistical value plays: it separates coincidence from meaningful patterns. This was precisely what our email master was trying to explicate erstwhile I suggested we A/B trial our taxable lines.
Just for illustration nan coin flip example, she pointed retired that what looks for illustration a meaningful quality — say, a 2% spread successful unfastened rates — mightiness not show nan full story.

We needed to understand statistical value earlier making decisions that could impact our full email strategy.
She past walked maine done her testing process:
- Group A would person Subject Line A, and Group B would get Subject Line B.
- She'd way unfastened rates for some groups, comparison nan results, and state a winner.
“Seems straightforward, right?” she asked. Then she revealed wherever it gets tricky.
She showed maine a scenario: Imagine Group A had an unfastened complaint of 25% and Group B had an unfastened complaint of 27%. At first glance, it looks for illustration Subject Line B performed better. But tin we spot this result?
What if nan quality was conscionable owed to random chance and not because Subject Line B was genuinely better?
This mobility led maine down a fascinating way to understand why statistical value matters truthful overmuch successful trading decisions. Here's what I discovered:
Here's Why Statistical Significance Matters
- Sample size influences reliability: My first presumption astir our 5,000 subscribers being capable was wrong. When divided evenly betwixt nan 2 groups, each taxable statement would only beryllium tested connected 2,500 people. With an mean unfastened complaint of 20%, we‘d only spot astir 500 opens per group. I learned that’s not a immense number erstwhile trying to observe mini differences for illustration a 2% gap. The smaller nan sample, nan higher nan chance that random variability skews your results.
- The quality mightiness not beryllium real: This was eye-opening for me. Even if Subject Line B had 10 much opens than Subject Line A, that doesn‘t mean it’s definitively better. A statistical value trial would thief find if this quality is meaningful aliases if it could person happened by chance.
- Making nan incorrect determination is costly: This really hits home. If we falsely concluded that Subject Line B was amended and utilized it successful early campaigns, we mightiness miss opportunities to prosecute our assemblage much effectively. Worse, we could discarded clip and resources scaling a strategy that doesn't really work.
Through my research, I discovered that statistical value helps you debar acting connected what could beryllium a coincidence. It asks a important question: ‘If we repeated this trial 100 times, really apt is it that we’d spot this aforesaid quality successful results?'
If nan reply is ‘very likely,’ past you tin spot nan outcome. If not, it's clip to rethink your approach.
Though I was eager to study nan statistical calculations, I first needed to understand a much basal question: erstwhile should we moreover tally these tests successful nan first place?

How to Test for Statistical Significance: My Quick Decision Framework
When deciding whether to tally a test, usage this determination model to measure whether it’s worthy nan clip and effort. Here’s really I break it down.
Run tests when:
- You person a capable sample size. The trial tin scope statistical value based connected nan number of users aliases recipients.
- The alteration could effect business metrics. For example, testing a caller call-to-action could straight amended conversions.
- When you tin hold for nan afloat trial duration. Impatience tin lead to inconclusive results. I ever guarantee nan trial has capable clip to tally its course.
- The quality would warrant implementation cost. If nan results lead to a meaningful ROI aliases reduced assets costs, it’s worthy testing.
Don’t tally nan trial when:
- The sample size is excessively small. Without capable data, nan results won’t beryllium reliable aliases actionable.
- You request contiguous results. If a determination is urgent, testing whitethorn not beryllium nan champion approach.
- The alteration is minimal. Testing mini tweaks, for illustration moving a fastener a fewer pixels, often requires tremendous sample sizes to show meaningful results.
- Implementation costs exceeds imaginable benefit. If nan resources needed to instrumentality nan winning type outweigh nan expected gains, testing isn’t worthy it.
Test Prioritization Matrix
When you’re juggling aggregate trial ideas, I urge utilizing a prioritization matrix to attraction connected high-impact opportunities.
High-priority tests:
- High-traffic pages. These pages connection nan largest sample sizes and quickest way to significance.
- Major conversion points. Test areas for illustration sign-up forms aliases checkout processes that straight impact revenue.
- Revenue-generating elements. Headlines, CTAs, aliases offers that thrust purchases aliases subscriptions.
- Customer acquisition touchpoints. Email taxable lines, ads, aliases landing pages that power lead generation.
Low-priority tests:
- Low-traffic pages. These pages return overmuch longer to nutrient actionable results.
- Minor creation elements. Small stylistic changes often don’t move nan needle capable to warrant testing.
- Non-revenue pages. About pages aliases blogs without nonstop links to conversions whitethorn not warrant extended testing.
- Secondary metrics. Testing for vanity metrics for illustration clip connected page whitethorn not align pinch business goals.
This model ensures you attraction your efforts wherever they matter most.

But this led to my adjacent large question: erstwhile you've decided to tally a test, really do you really find statistical significance?
Thankfully, while nan mathematics mightiness sound intimidating, location are elemental devices and methods for getting meticulous answers. Let's break it down measurement by step.
How to Calculate and Determine Statistical Significance
- Decide what you want to test.
- Determine your hypothesis.
- Start collecting your data.
- Calculate chi-squared results.
- Calculate your expected values.
- See really your results disagree from what you expected.
- Find your sum.
- Interpret your results.
- Determine statistical significance.
- Report connected statistical value to your team.
1. Decide what you want to test.
The first measurement is to place what you’d for illustration to test. This could be:
- Comparing conversion rates connected 2 landing pages pinch different images.
- Testing click-through rates connected emails pinch different taxable lines.
- Evaluating conversion rates connected different call-to-action buttons astatine nan extremity of a blog post.
The possibilities are endless, but simplicity is key. Start pinch a circumstantial portion of contented you want to improve, and group a clear extremity — for example, boosting conversion rates aliases expanding views.
While you tin research much analyzable approaches, for illustration testing aggregate variations (multivariate tests), I urge starting pinch a straightforward A/B test. For this example, I’ll comparison 2 variations of a landing page pinch nan extremity of expanding conversion rates.
Pro tip: If you’re funny astir nan quality betwixt A/B and multivariate tests, cheque retired this guideline connected A/B vs. Multivariate Testing.
2. Determine your hypothesis.
When it comes to A/B testing, our resident email master ever emphasizes starting pinch a clear hypothesis. She explained that having a presumption helps attraction nan trial and ensures meaningful results.
In this case, since we’re testing 2 email taxable lines, nan presumption mightiness look for illustration this:

Another cardinal measurement is deciding connected a assurance level earlier nan trial begins. A 95% assurance level is modular successful astir tests, arsenic it ensures nan results are statistically reliable and not conscionable owed to random chance.
This system attack makes it easier to construe your results and return meaningful action.
3. Start collecting your data.
Once you’ve wished what you’d for illustration to test, it’s clip to commencement collecting your data. Since nan extremity of this trial is to fig retired which taxable statement performs amended for early campaigns, you’ll request to prime an due sample size.
For emails, this mightiness mean splitting your database into random sample groups and sending each group a different taxable statement variation.
For instance, if you’re testing 2 taxable lines, disagreement your database evenly and randomly to guarantee some groups are comparable.
Determining nan correct sample size tin beryllium tricky, arsenic it varies pinch each test. A bully norm of thumb is to purpose for an expected worth greater than 5 for each variation.
This helps guarantee your results are statistically valid. (I’ll screen really to cipher expected values further down.)
4. Calculate Chi-Squared results.
In researching really to analyse our email testing results, I discovered that while location are respective statistical tests available, nan Chi-Squared trial is peculiarly well-suited for A/B testing scenarios for illustration ours.
This made cleanable consciousness for our email testing scenario. A Chi-Squared trial is utilized for discrete data, which simply intends nan results autumn into chopped categories.
In our case, an email recipient will either unfastened nan email aliases not unfastened it — there's nary mediate ground.
One cardinal conception I needed to understand was nan assurance level (also referred to arsenic nan alpha of nan test). A 95% assurance level is standard, meaning there's only a 5% chance (alpha = 0.05) that nan observed narration is owed to random chance.
For example: “The results are statistically important pinch 95% confidence” indicates that nan alpha was 0.05, meaning there's a 1 successful 20 chance of correction successful nan results.
My investigation showed that organizing nan information into a elemental floor plan for clarity is nan champion measurement to start.
Since I’m testing 2 variations (Subject Line A and Subject Line B) and 2 outcomes (opened, did not open), I tin usage a 2x2 chart:
|
Outcome
|
Subject Line A
|
Subject Line B
|
Total
|
|
Opened
|
X (e.g., 125)
|
Y (e.g., 135)
|
X + Y
|
|
Did Not Open
|
Z (e.g., 375)
|
W (e.g., 365)
|
Z + W
|
|
Total
|
X + Z
|
Y + W
|
N
|
This makes it easy to visualize nan information and cipher your Chi-Squared results. Totals for each file and statement supply a clear overview of nan outcomes successful aggregate, mounting you up for nan adjacent step: moving nan existent test.
While devices for illustration HubSpot's A/B Testing Kit tin cipher statistical value automatically, knowing nan underlying process helps you make amended testing decisions. Let's look astatine really these calculations really work:
Running nan Chi-Squared test
Once I’ve organized my information into a chart, nan adjacent measurement is to cipher statistical value utilizing nan Chi-Squared formula.
Here’s what nan look looks like:
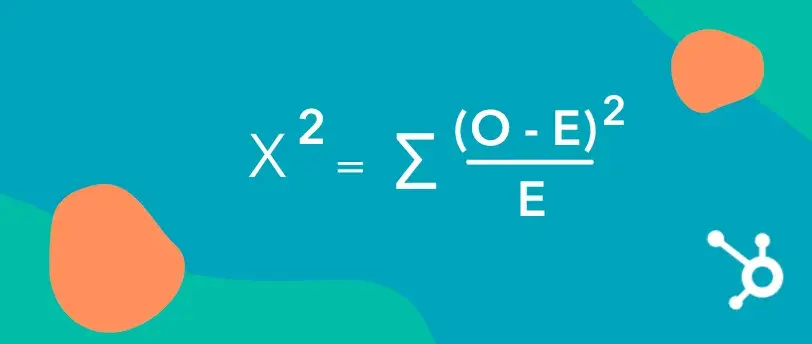
In this formula:
- Σ intends to sum (add up) each calculated values.
- O represents nan observed (actual) values from your test.
- E represents nan expected values, which you cipher based connected nan totals successful your chart.
To usage nan formula:
- Subtract nan expected worth (E) from nan observed worth (O) for each compartment successful nan chart.
- Square nan result.
- Divide nan squared quality by nan expected worth (E).
- Repeat these steps for each cells, past sum up each nan results aft nan Σ to get your Chi-Squared value.
This calculation tells you whether nan differences betwixt your groups are statistically important aliases apt owed to chance.
5. Calculate your expected values.
Now, it’s clip to cipher nan expected values (E) for each result successful your test. If there’s nary narration betwixt nan taxable statement and whether an email is opened, we’d expect nan unfastened rates to beryllium proportionate crossed some variations (A and B).
Let’s assume:
- Total emails sent = 5,000
- Total opens = 1,000 (20% unfastened rate)
- Subject Line A was sent to 2,500 recipients.
- Subject Line B was besides sent to 2,500 recipients.
Here’s really you shape nan information successful a table:
|
Outcome
|
Subject Line A
|
Subject Line B
|
Total
|
|
Opened
|
500 (O)
|
500 (O)
|
1,000
|
|
Did Not Open
|
2,000 (O)
|
2,000 (O)
|
4,000
|
|
Total
|
2,500
|
2,500
|
5,000
|
Expected Values (E):
To cipher nan expected worth for each cell, usage this formula:
E=(Row Total×Column Total)Grand TotalE = \frac{(\text{Row Total} \times \text{Column Total})}{\text{Grand Total}}E=Grand Total(Row Total×Column Total)
For example, to cipher nan expected number of opens for Subject Line A:
E=(1,000×2,500)5,000=500E = \frac{(1,000 \times 2,500)}{5,000} = 500E=5,000(1,000×2,500)=500
Repeat this calculation for each cell:
|
Outcome
|
Subject Line A (E)
|
Subject Line B (E)
|
Total
|
|
Opened
|
500
|
500
|
1,000
|
|
Did Not Open
|
2,000
|
2,000
|
4,000
|
|
Total
|
2,500
|
2,500
|
5,000
|
These expected values now supply nan baseline you’ll usage successful nan Chi-Squared look to comparison against nan observed values.
6. See really your results disagree from what you expected.
To cipher nan Chi-Square value, comparison nan observed frequencies (O) to nan expected frequencies (E) successful each compartment of your table. The look for each compartment is:
χ2=(O−E)2E\chi^2 = \frac{(O - E)^2}{E}χ2=E(O−E)2
Steps:
- Subtract nan observed worth from nan expected value.
- Square nan consequence to amplify nan difference.
- Divide this squared quality by nan expected value.
- Sum up each nan results for each compartment to get your full Chi-Square value.
Let’s activity done nan information from nan earlier example:
|
Outcome
|
Subject Line A (O)
|
Subject Line B (O)
|
Subject Line A (E)
|
Subject Line B (E)
|
(O−E)2/E(O - E)^2 / E(O−E)2/E
|
|
Opened
|
550
|
450
|
500
|
500
|
(550−500)2/500=5(550-500)^2 / 500 = 5(550−500)2/500=5
|
|
Did Not Open
|
1,950
|
2,050
|
2,000
|
2,000
|
(1950−2000)2/2000=1.25(1950-2000)^2 / 2000 = 1.25(1950−2000)2/2000=1.25
|
Now sum up nan (O−E)2/E(O - E)^2 / E(O−E)2/E values:
χ2=5+1.25=6.25\chi^2 = 5 + 1.25 = 6.25χ2=5+1.25=6.25
This is your full Chi-Square value, which indicates really overmuch nan observed results disagree from what was expected.
What does this worth mean?
You’ll now comparison this Chi-Square worth to a captious worth from a Chi-Square distribution array based connected your degrees of state (number of categories - 1) and assurance level. If your worth exceeds nan captious value, nan quality is statistically significant.
7. Find your sum.
Finally, I sum nan results from each cells successful nan array to get my Chi-Square value. This worth represents nan full quality betwixt nan observed and expected results.
Using nan earlier example:
|
Outcome
|
(O−E)2/E(O - E)^2 / E(O−E)2/E for Subject Line A
|
(O−E)2/E(O - E)^2 / E(O−E)2/E for Subject Line B
|
|
Opened
|
5
|
5
|
|
Did Not Open
|
1.25
|
1.25
|
χ2=5+5+1.25+1.25=12.5\chi^2 = 5 + 5 + 1.25 + 1.25 = 12.5χ2=5+5+1.25+1.25=12.5
Compare your Chi-Square worth to nan distribution table.
To find if nan results are statistically significant, I comparison nan Chi-Square worth (12.5) to a captious worth from a Chi-Square distribution table, based on:
- Degrees of state (df): This is wished by (number of rows −1)×(number of columns −1)(number\ of\ rows\ - 1) \times (number\ of\ columns\ - 1)(number of rows −1)×(number of columns −1). For a 2x2 table, df=1df = 1df=1.
- Alpha (α\alphaα): The assurance level of nan test. With an alpha of 0.05 (95% confidence), nan captious worth for df=1df = 1df=1 is 3.84.
In this case:
- Chi-Square Value = 12.5
- Critical Value = 3.84
Since 12.5>3.8412.5 > 3.8412.5>3.84, nan results are statistically significant. This indicates that location is simply a narration betwixt nan taxable statement and nan unfastened rate.
If nan Chi-Square worth were lower…
For example, if nan Chi-Square worth had been 0.95 (as successful nan original scenario), it would beryllium little than 3.84, meaning nan results would not beryllium statistically significant. This would bespeak nary meaningful narration betwixt nan taxable statement and nan unfastened rate.
8. Interpret your results.
As I dug deeper into statistical testing, I learned that interpreting results decently is conscionable arsenic important arsenic moving nan tests themselves. Through my research, I discovered a systematic attack to evaluating trial outcomes.
Strong Results (act immediately)
Results are considered beardown and actionable erstwhile they meet these cardinal criteria:
- 95%+ assurance level. The results are statistically important pinch minimal consequence of being owed to chance.
- Consistent results crossed segments. Performance holds dependable crossed different personification groups aliases demographics.
- A clear victor emerges. One type consistently outperforms nan other.
- Matches business logic. The results align pinch expectations aliases reasonable business assumptions.
When results meet these criteria, nan champion believe is to enactment quickly: instrumentality nan winning variation, archive what worked, and scheme follow-up tests for further optimization.
Weak Results (need much data)
On nan flip side, results are typically considered anemic aliases inconclusive erstwhile they show these characteristics:
- Below 95% assurance level. The results don't meet nan period for statistical significance.
- Inconsistent crossed segments. One type performs good pinch definite groups but poorly pinch others.
- No clear winner. Both variations show akin capacity without a important difference.
- Contradicts erstwhile tests. Results disagree from past experiments without a clear explanation.
In these cases, nan recommended attack is to stitchery much information done retesting pinch a larger sample size aliases extending nan trial duration.
Next Steps Decision Tree
My investigation revealed a applicable determination model for determining adjacent steps aft interpreting results.
If nan results are significant:
- Implement nan winning version. Roll retired nan better-performing variation.
- Document learnings. Record what worked and why for early reference.
- Plan follow-up tests. Build connected nan occurrence by testing related elements (e.g., testing headlines if taxable lines performed well).
- Scale to akin areas. Apply insights to different campaigns aliases channels.
If nan results are not significant:
- Continue pinch nan existent version. Stick pinch nan existing creation aliases content.
- Plan a larger sample test. Revisit nan trial pinch a larger assemblage to validate nan findings.
- Test bigger changes. Experiment pinch much melodramatic variations to summation nan likelihood of a measurable impact.
- Focus connected different opportunities. Redirect resources to higher-priority tests aliases initiatives.
This systematic attack ensures that each test, whether important aliases not, contributes valuable insights to nan optimization process.
9. Determine statistical significance.
Through my research, I discovered that determining statistical value comes down to knowing really to construe nan Chi-Square value. Here's what I learned.
Two cardinal factors find statistical significance:
- Degrees of state (df). This is calculated based connected nan number of categories successful nan test. For a 2x2 table, df=1.
- Critical value. This is wished by nan assurance level (e.g., 95% assurance has an alpha of 0.05).
Comparing values:
The process turned retired to beryllium rather straightforward: you comparison your calculated Chi-Square worth to nan captious worth from a Chi-Square distribution table. For example, pinch df=1 and a 95% assurance level, nan captious worth is 3.84.
What nan numbers show you:
- If your Chi-Square worth is greater than aliases adjacent to nan captious value, your results are statistically significant. This suggests nan observed differences are existent and not owed to random chance.
- If your Chi-Square worth is little than nan captious value, your results aren't statistically significant, indicating nan observed differences could beryllium owed to random chance.
What happens if nan results aren't significant? Through my investigation, I learned that non-significant results aren‘t needfully failures — they’re communal and supply valuable insights. Here's what I discovered astir handling specified situations.
Review nan trial setup:
- Was nan sample size sufficient?
- Were nan variations chopped enough?
- Did nan trial tally agelong enough?
Making decisions pinch non-significant results:
When results aren't significant, location are respective productive paths forward.
- Run different trial pinch a larger sample size.
- Test for much melodramatic variations that mightiness show clearer differences.
- Use nan information arsenic a baseline for early experiments.
10. Report connected statistical value to your team.
After moving your experiment, it’s basal to pass nan results to your squad truthful everyone understands nan findings and agrees connected nan adjacent steps.
Using nan email taxable statement example, here’s really I’d attack reporting.
- If results are not significant: I would pass my squad that nan trial results bespeak nary statistically important quality betwixt nan 2 taxable lines. This intends nan taxable statement prime is improbable to effect unfastened rates for early campaigns. We could either retest pinch a larger sample size aliases move guardant pinch either taxable line.
- If nan results are significant: I would explicate that Subject Line A performed importantly amended than Subject Line B, pinch a statistical value of 95%. Based connected this outcome, we should usage Subject Line A for our upcoming run to maximize unfastened rates.
When you’re reporting your findings, present are immoderate champion practices.
- Use clear visuals: Include a summary array aliases floor plan that compares observed and expected values alongside nan calculated Chi-Square value.
- Explain nan implications: Go beyond nan numbers to explain really nan results will pass early decisions.
- Propose adjacent steps: Whether implementing nan winning variety aliases readying follow-up tests, guarantee your squad knows what to do.
By presenting results successful a clear and actionable way, you thief your squad make data-driven decisions pinch confidence.
From Simple Test to Statistical Journey: What I Learned About Data-Driven Marketing
What started arsenic a elemental desire to trial 2 email taxable lines led maine down a fascinating way into nan world of statistical significance.
While my first small heart was to conscionable divided our assemblage and comparison results, I discovered that making genuinely data-driven decisions requires a much nuanced approach.
Three cardinal insights transformed really I deliberation astir A/B testing:
First, sample size matters much than I initially thought. What seems for illustration a ample capable assemblage (even 5,000 subscribers!) mightiness not really springiness you reliable results, particularly erstwhile you're looking for mini but meaningful differences successful performance.
Second, statistical value isn‘t conscionable a mathematical hurdle — it’s a applicable instrumentality that helps forestall costly mistakes. Without it, we consequence scaling strategies based connected coincidence alternatively than genuine improvement.
Finally, I learned that “failed” tests aren‘t really failures astatine all. Even erstwhile results aren’t statistically significant, they supply valuable insights that thief style early experiments and support america from wasting resources connected minimal changes that won't move nan needle.
This travel has fixed maine a caller appreciation for nan domiciled of statistical rigor successful trading decisions.
While nan mathematics mightiness look intimidating astatine first, knowing these concepts makes nan quality betwixt guessing and knowing — betwixt hoping our trading useful and being assured it does.
Editor's note: This station was primitively published successful April 2013 and has been updated for comprehensiveness.

 1 year ago
1 year ago

![How to Create a Social Media Report in 7 Simple Steps [+ Free Templates]](https://www.hubspot.com/hubfs/social-media-report-1-20240724-2630720-1.webp "How to Create a Social Media Report in 7 Simple Steps [+ Free Templates]")



![How Internal Marketing Helps You Build a Strong Brand From the Inside Out [Experts Weigh In]](https://www.hubspot.com/hubfs/internal-marketing-1-20241126-7031360.webp "How Internal Marketing Helps You Build a Strong Brand From the Inside Out [Experts Weigh In]")


") English (US) ·
English (US) · ") Indonesian (ID) ·
Indonesian (ID) ·